
The Blog Is Writing Itself. Here's Day 2.
What I learned in the week between pressing publish and actually shipping reliably.

A week ago I wrote about building an autonomous AI blog pipeline. Four AI models wired together in n8n, designed to monitor 10 YouTube channels and synthesize working notes published automatically to my site. Day 1 ended with the pipeline built and tested manually. The bones worked.
Day 2 was supposed to be about going from “tested” to “live.” It ended up teaching me more than I expected.
Pressing publish was the easy part. What came after was the actual learning.
The bug in the first output
The very first post the system generated had a tell. Buried in the third paragraph:
“The source video gets into this from a builder’s angle, and it lined up with something I’ve been chewing on for weeks.”
There it was. The source video. The whole point of the architecture is that the YouTube transcripts are research material, not subject matter. They’re scaffolding I’m reading to identify topics worth writing about. A post that says “the source video” is fundamentally a summary of someone else’s content, not original thinking.
It read like AI. Worse, it read like derivative AI. Exactly what Google’s helpful content updates were designed to penalize.
I caught it before publishing. The manual review on Day 1 was specifically so I could catch things like this. But the fix wasn’t trivial.
Why one behavior needed three fixes
You’d think you could fix “stop saying ‘the source video’” with a one-line addition to the prompt. You can’t. Here’s what it actually took:
Fix one: the writing prompt. Added explicit bans on “the source video,” “this video,” “the channel,” “the speaker,” and a dozen variations. Spelled out the philosophy: the transcript is research, not subject matter. The reader should never know a video informed the post.
Fix two: how the transcript was framed. The original instructions to the writing model literally labeled the transcript “Source video:” with the channel name and URL at the top. That framing was telling the model “this video is what you’re writing about.” I stripped all of that out. Reframed the transcript as “Research material that informed this topic” with explicit “do not reference this directly” instructions.
Fix three: the quality gate. Added source material references to the list of critical fails that the second AI must catch. Now even if a future prompt change causes the writing model to slip up, the gate auto-queues anything that mentions “the source video” for human review before publishing. Defense in depth.
The lesson: AI system failures often need fixes in multiple places. Where the model picks up the bad pattern. Where the input primes it for the bad pattern. Where you catch the failure if both upstream fixes fail. Single-point fixes feel cleaner. They’re fragile.
The Practitioner’s Take rule
The other big addition: every post must end with what I started calling a “Practitioner’s Take.” Not labeled with a heading. Just a closing paragraph that adds applied analysis instead of summary.
Generic AI-generated content tends to close with a summary or a “what this means going forward” platitude. That’s the gravity. Forcing the model to write something specific (what would you actually try, what’s the implication for someone shipping today, what’s the catch most readers miss) pulls it out of summary mode and into practitioner mode.
This is the move that separates a working note from a transcript paraphrase.

Feeling the system breathe
Going from manual to scheduled isn’t just flipping a switch. It means you need the system to tell you what’s happening when you’re not watching.
Telegram is my interface to the pipeline. Every successful post pings my phone with the title, the gate score, the verdict reason, any flags. Every queued post tells me what failed and why. I can feel the system breathing from my pocket.
This is the part most “AI agent” demos skip. A system you can’t observe is a system you can’t trust. The notifications are what let me let it run.
Pressing publish
When I activated the schedule trigger, the pipeline went from a thing I run to a thing that runs.
That’s a real shift. The work changes shape. Instead of building, it becomes watching, reading, tuning. Less typing, more judgment. Less code, more taste.
The system is now generating up to 3 posts per day, on a 6-hour cadence, with the quality gate filtering anything below 30 out of 40. Posts that pass go live within 90 seconds. Posts that don’t go to a draft queue I can review.
But pressing publish wasn’t the finish line. It was the start of the actual learning.
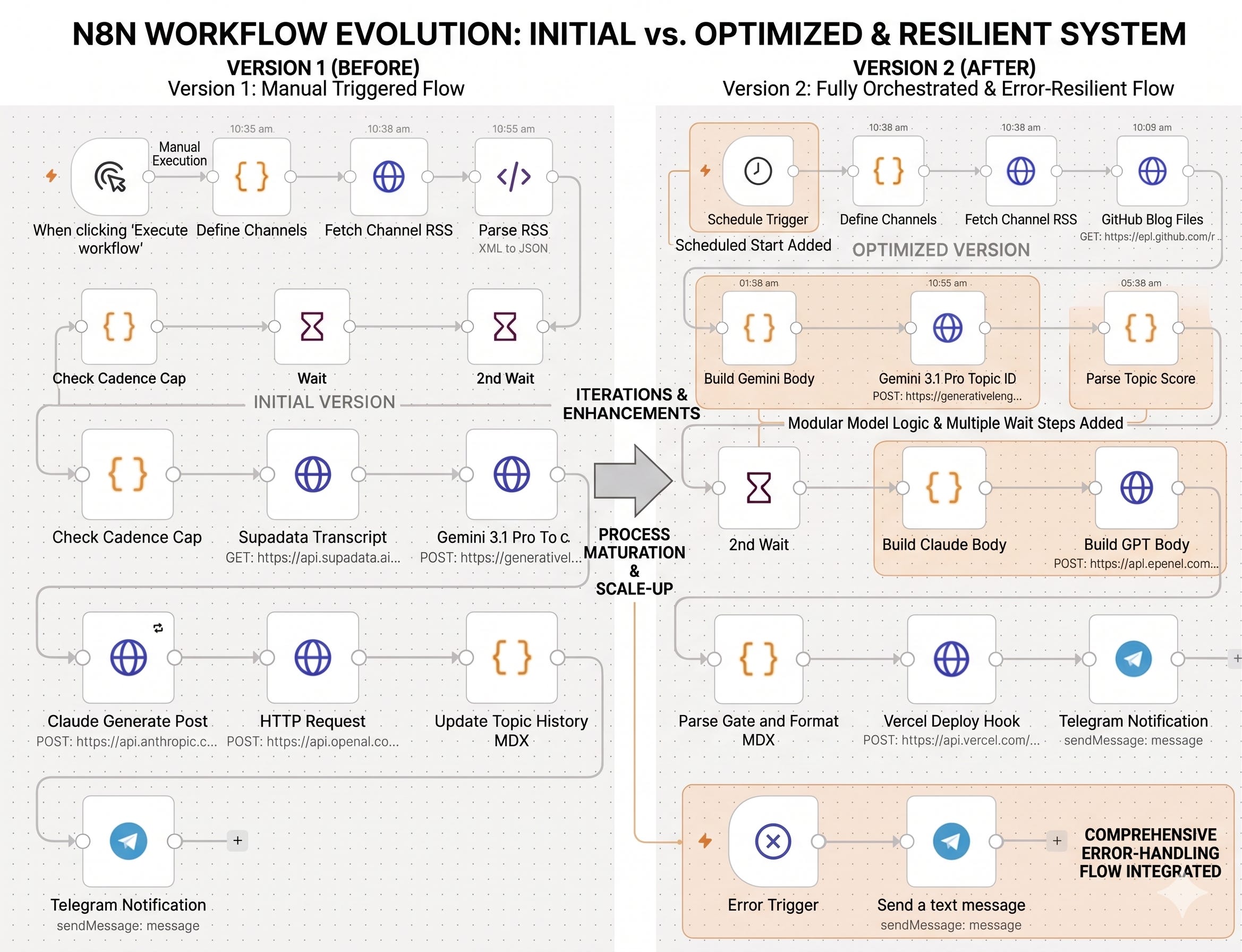
Three things real production taught me
Within the first 48 hours of the schedule firing, three problems surfaced that I hadn’t designed around. Each became its own small lesson.
Real data isn’t clean data. My topic-identification call was breaking on actual YouTube transcripts because they contain quotation marks, special characters, and other things that messed up how the API requests were being constructed. Worked fine in testing because my test transcripts were clean. Broke immediately with real ones. The fix was rebuilding that part of the pipeline so it handles whatever weird text shows up in the wild. Once I rewrote it the right way, I applied the same pattern to my writing and quality-gate calls too. Three brittle pieces became three reliable ones.
Real APIs are flakier than test APIs. Anthropic occasionally returns “overloaded” errors when their servers are busy. Doesn’t happen in light testing. Happens regularly when a scheduled run hits at peak times. The fix was tiny: small pauses between heavy API calls, so the pipeline doesn’t burst requests. Costs 30 seconds per run. Saves an entire run when it would otherwise fail.
A system that runs without you needs to tell you when it’s struggling. I had notifications on success but nothing on failure. If a node errored, I’d find out only by checking the workflow manually. Added an automatic error alert path. Now if anything in any node fails, my phone tells me which node and what the error was. Failures are now a notification, not a silence.
The pattern across all three: production exposes gaps that testing misses. Real data is messier than test data. Real APIs are flakier than mocks. Real schedules trigger bursts that manual runs never would. Building the resilience layer is mostly defending against this kind of variability.
What this is really about
The blog is one experiment. There will be more.
The whole point of this project is to build with AI in public. To learn what works by shipping it. To see what surprises me when a system runs without my hands on it. Every fix this week taught me something I wouldn’t have learned by reading about autonomous content pipelines. Every surprise was a piece of knowledge that didn’t exist for me before I shipped.
That’s the work I want to be doing. Build the thing. Watch it run. Fix what breaks. Take notes. Build the next thing with everything you learned from this one.
If you missed Day 1, here’s how the whole pipeline got designed and built.
The blog itself is at kenashe.ai/blog. This newsletter is where the longer-form essays come out. Subscribe if you want to follow what comes next.