
I'm Building a Blog That Writes Itself. Here's Day 1.
Four AI models, eighteen n8n nodes, and the Claude usage cap that forced a mid-build Gemini pivot.

Yesterday I started on the most ambitious AI build I’ve attempted: an autonomous blog that monitors a curated set of YouTube channels for new AI content, picks the most interesting angle from each video, writes a 600 to 1000-word post in my editorial voice, runs that post through a second AI for quality review, and publishes the survivors to my site automatically. Three posts a day, cap enforced. No human in the loop unless the quality gate flags something for review.
The live version is at kenashe.ai/blog. As I write this, the pipeline has been built end to end and tested manually. Day 2 is switching from manual to scheduled triggers and tuning the prompts based on what the first real batch of output looks like.
Below: the plan, the tools, what got built on Day 1, and where I hit a wall.
The plan
The goal is something every marketer should be paying attention to in 2026: a content engine that runs without me. Not “AI-assisted blog posts that I edit and publish.” Autonomous posts that go live without my fingers touching them, gated by quality controls that catch the bad ones before they ship.
Specifically:
Monitor 10 curated YouTube channels in AI and digital marketing for new uploads
Pull transcripts for new videos posted in the last 48 hours
Identify the single best angle worth a 600 to 1000-word post (most videos don’t have one, reject those)
Generate the post in my voice, structured for SEO, with frontmatter ready for Astro
Score it on a 40-point rubric (originality, voice match, factual defensibility, reader value)
Auto-publish if it passes, queue for review if it doesn’t
Cap at 3 posts per day
Notify me on every result so I can pull anything that slipped through
Why three a day, not ten or twenty? Google’s helpful content updates have been brutal to high-volume AI content that doesn’t add value beyond its sources. Three good posts daily for a month gives Google enough data to start ranking the domain. Three good plus seven mediocre gets the whole domain penalized. The cap is the SEO insurance policy.
The tools
I’m running four AI models plus a stack of services. Each has a specific job:
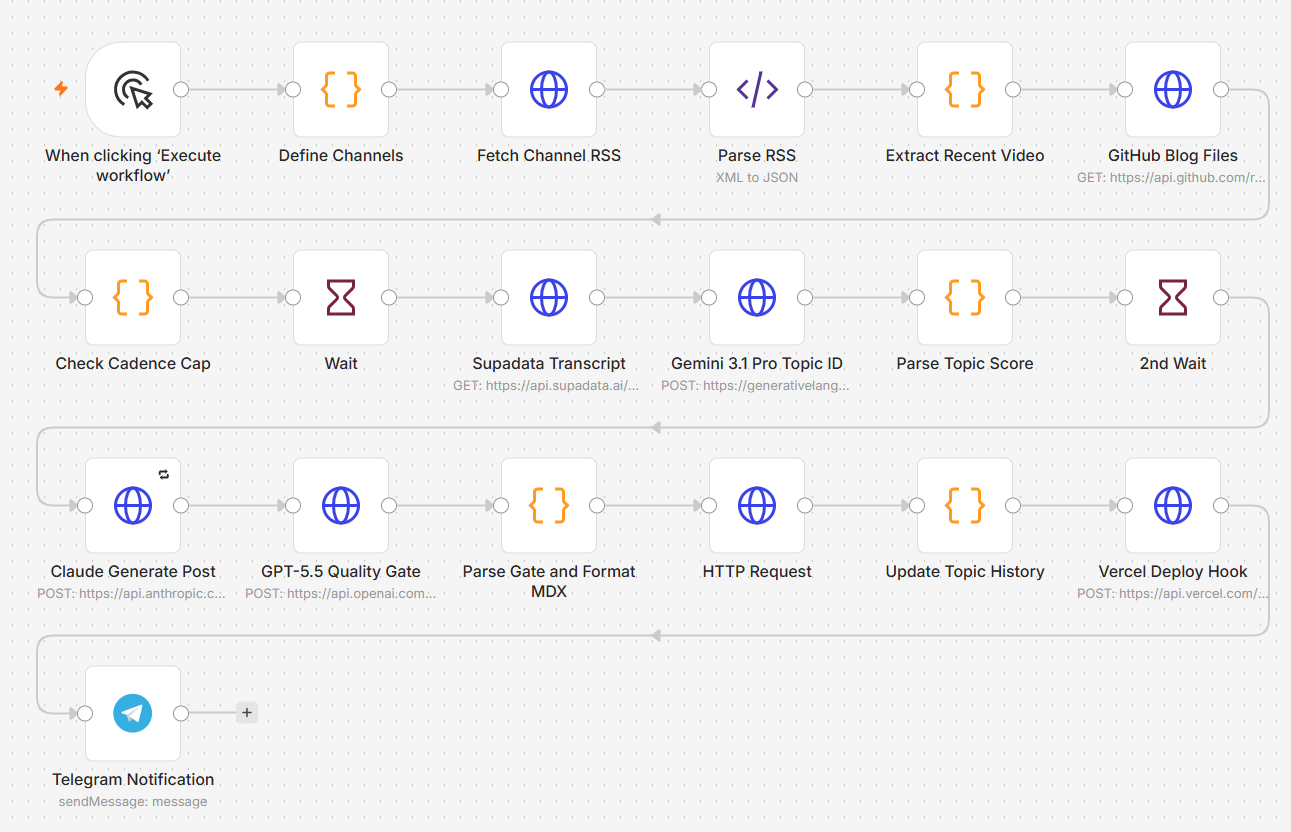
n8n is the orchestration layer. It’s a workflow automation tool similar to Zapier or Make, but more flexible and self-hostable. The entire pipeline lives as a single n8n workflow with 18 nodes. n8n calls the APIs, passes data between them, handles error states, and (starting today) runs on a schedule.
Claude Opus 4.7 (via the Anthropic API) is the writing engine. When I tested both Claude and GPT-5.5 against the same source material, Claude produced posts that read more like a real person and less like a press release. For long-form writing in a specific voice, it’s still the best.
Gemini 3.1 Pro does topic identification. This is the upstream filter that decides whether a video is worth writing about at all. Most videos aren’t. Gemini reads the transcript, identifies the single most interesting angle, scores it on novelty, search potential, and audience fit. If the angle scores below 21 out of 30, the workflow skips it and waits for the next video.
GPT-5.5 is the quality gate. After Claude writes a post, GPT-5.5 reviews it on a 40-point rubric and decides whether it ships or gets queued for human review. Using a different model for review than for writing is the key insight. Each model has different blind spots. The same model can’t reliably catch its own mistakes.
Supadata handles YouTube transcript extraction. Cheap, reliable, simple HTTP API. About half a cent per transcript.
GitHub and Vercel are the publishing pipeline. n8n commits new posts as Astro MDX files to my GitHub repo. Vercel detects the push and rebuilds the live site in about 90 seconds. The whole site auto-deploys with no manual step.
Telegram is where notifications land. Every published post and every queued draft pings my phone with the score, the reason, and a link to read or pull.
Worth mentioning: this site itself was built with Claude Code (and reviewed by Codex, OpenAI’s coding agent) over a weekend before this automation went on top of it. That’s the foundation the blog pipeline is committing into.
Day 1: what got built
Day 1 was about laying down the pipeline end to end. The full architecture went in: define channels, fetch RSS feeds, parse, extract latest videos, dedupe against history, check the daily cadence cap, fetch transcripts, score topics with Gemini, generate posts with Claude, gate with GPT-5.5, format as MDX with a date-prefixed slug, commit to GitHub, trigger Vercel, and ping me on Telegram.
Eighteen nodes in n8n. Most of the build time was on three things: getting the cross-node data references right (n8n’s expression syntax has gotchas, and node naming matters more than I expected), wiring up the API authentications for five different services, and debugging a stubborn 404 from GitHub that turned out to be a token scope issue rather than anything in my code.
The hardest single piece to get right was the slug generation. The original plan generated slugs from the post title alone, which would have caused GitHub collisions any time two posts had similar titles. I switched to a date-prefixed format like 2026-05-14-title-slug so collisions are functionally impossible. Two posts can’t share a slug across different days, and the daily cap prevents same-day collisions in practice.
By end of Day 1, the pipeline runs end-to-end on a manual trigger. New video → new post → on the live site within minutes. That’s the bones working.
The Claude usage cap, and the Gemini pivot
About halfway through the build, I hit Anthropic’s usage cap. I’d been using Claude as my pair-programming assistant for the whole build (separate from Claude Opus 4.7 as the writing engine inside the pipeline). The cap fired with a couple of hours of work left, and I was already paying for overage.
Two options at that point: keep paying for more overage, or pivot to a different assistant. I’d been wanting to test Gemini in a real working context anyway, so I switched mid-build. Gave Gemini the workflow JSON, the error messages, and asked it to help fix the remaining issues. Both models delivered. Different strengths, but the build kept moving.
Lesson: have a backup AI assistant configured before you need one. Not because any one of them is unreliable, but because hitting a usage cap mid-build is exactly when you don’t want to be configuring API keys for a new tool. The cost of having two assistants ready is roughly zero. The cost of being stuck is half a day.
Day 2: what’s left
A pipeline that only fires when I press a button isn’t autonomous. Day 2 is two things: switch the manual trigger to a scheduled trigger (every six hours), and tune the prompts based on actual output.
The prompts are the biggest lever in the whole system. Every time the first batch of posts has a phrase I wouldn’t write, that phrase goes into the banned list. Every time the gate misses something, the rubric gets tightened. After a week of tuning against real output, the system prompts will be twice as long as the Day 1 versions and the failure rate will be much lower.
The plan after Day 2 is to let it run for a week at three posts per day, watch the Search Console data, then decide whether to expand the channel set, raise the cadence cap, or add image generation. Anything I scale before seeing real ranking data is betting in the dark.
What this is proving
This whole project (building kenashe.ai with Claude Code and then this automation pipeline on top of it) is a real test of a real thesis. Application-layer AI work is no longer something only engineers can do. A digital marketer in 2026 who isn’t shipping AI-built systems is going to be outpaced by those who are.
The bar to entry isn’t the math. It isn’t the model weights. It isn’t the cost. It’s deciding that this is the work and putting in the hours. Twenty hours over a weekend gets you a custom site. Eight more hours gets you a blog that writes itself.
If you’re a marketer reading this and you’re not building, build.